|
I am a research fellow at the CBS-NTT Program in Physics of Intelligence at Harvard University, leading the phenomenological theory team and often collaborating with Hidenori Tanaka, David Krueger, and Demba Ba. I did my PhD co-affiliated with EECS, University of Michigan and CBS, Harvard, and was advised by Robert Dick and Hidenori Tanaka. I am generally interested in designing (faithful) abstractions of phenomena relevant to controlling or aligning neural networks. I am also very interested in better understanding training dynamics of neural networks, especially via a statistical physics perspective. I graduated with a Bachelor's degree in ECE from Indian Institute of Technology (IIT), Roorkee in 2019. My research in undergraduate was primarily focused on embedded systems, such as energy-efficient machine vision systems. Email / CV / Google Scholar / Github |

|
|
|
|
|
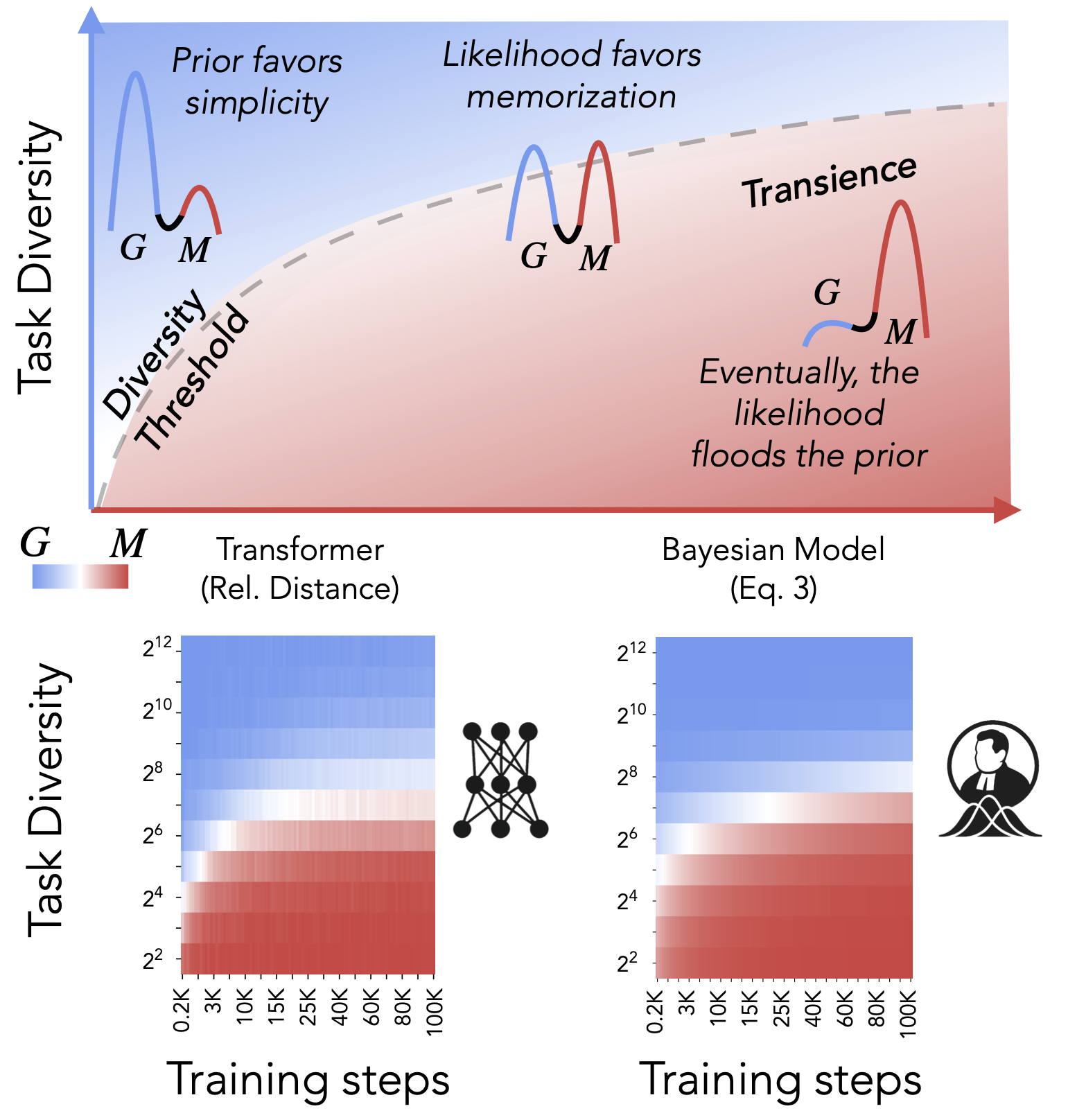
Daniel Wurgaft*, Ekdeep Singh Lubana*, Core Francisco Park, Hidenori Tanaka, Gautam Reddy, and Noah Goodman Preprint, 2025 We model ICL in a hierarchical Bayesian framework as a posterior-weighted average of two well-defined algorithmic strategies. Taking a rational analysis lens, we show across three popular setttings, that we can analytically predict model behavior and characterize the algorithmic phase-diagram identified in ICL in our prior work. |
|
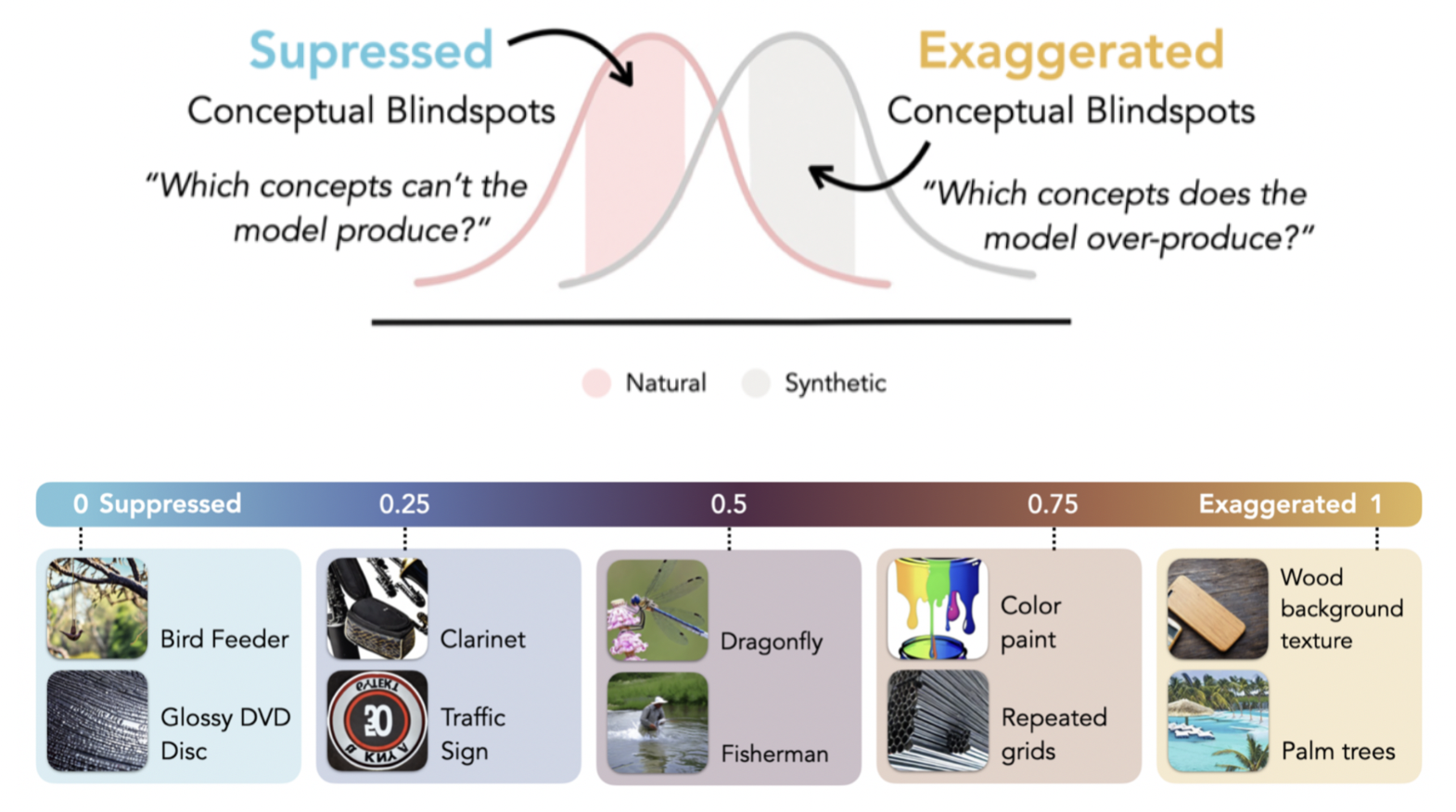
Matyas Bohacek*, Thomas Fel*, Maneesh Agrawala, and Ekdeep Singh Lubana Preprint, 2025 We build on results from identifiability theory to formalize a measure that assesses fine-grained differences in a natural distribution and a generative model trained upon it. |
|
Valerie Costa*, Thomas Fel*, Ekdeep Singh Lubana*, Bahareh Tolooshams, and Demba Ba Preprint, 2025 We use recent phenomenology of neural network representations, e.g., their ability to encode hierarchical and nonlinear concepts, to argue for the limitations of Linear representation hypothesis, contextualizing SAEs with respect to such concepts. |
|
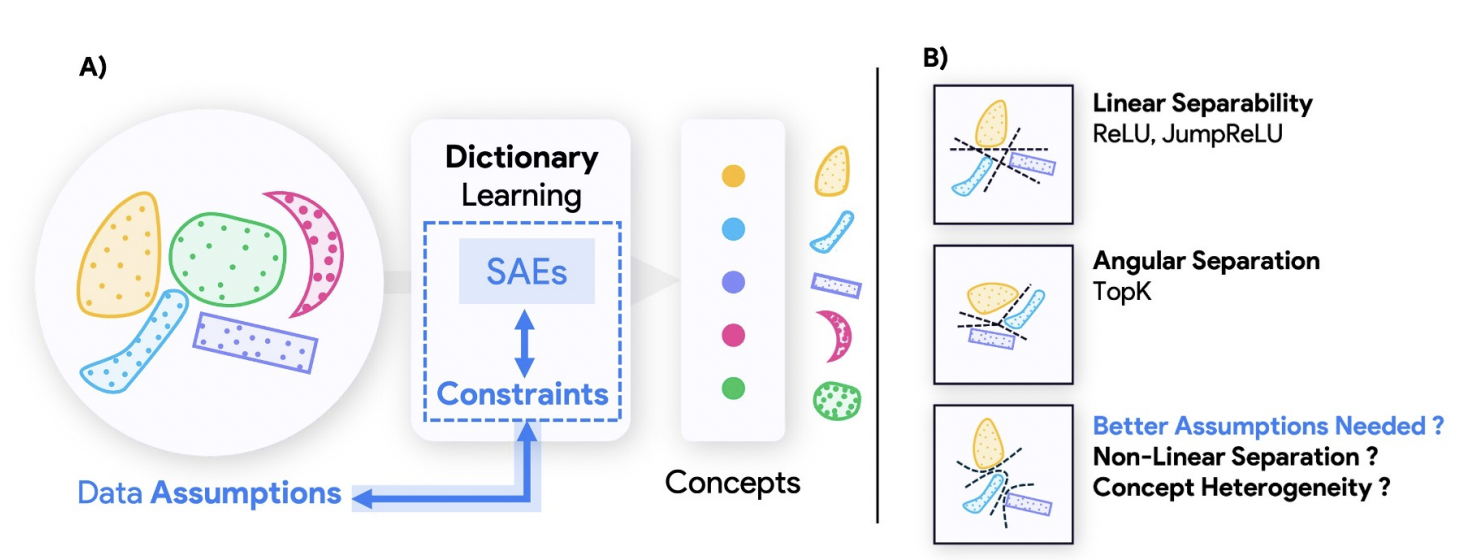
Sai Sumedh R. Hindupur*, Ekdeep Singh Lubana*, Thomas Fel*, and Demba Ba Preprint, 2025 We demonstrate a duality between how concepts are organized in model representations and the optimal SAE that will help identify them. This implies there exists no universally optimal SAE that can be used across models and domains. |
|
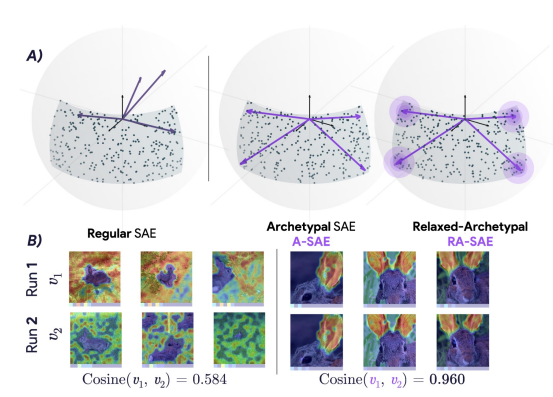
Thomas Fel*, Ekdeep Singh Lubana*, Jacob S. Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba Ba, and Talia Konkle International Conference on Machine Learning (ICML), 2025 We use vision models to demonstrate algorithmic instability in SAEs, i.e., different runs of the same pipeline yield different features / model interpretations. We propose a geometrical constraint to substantially address this issue. |
|
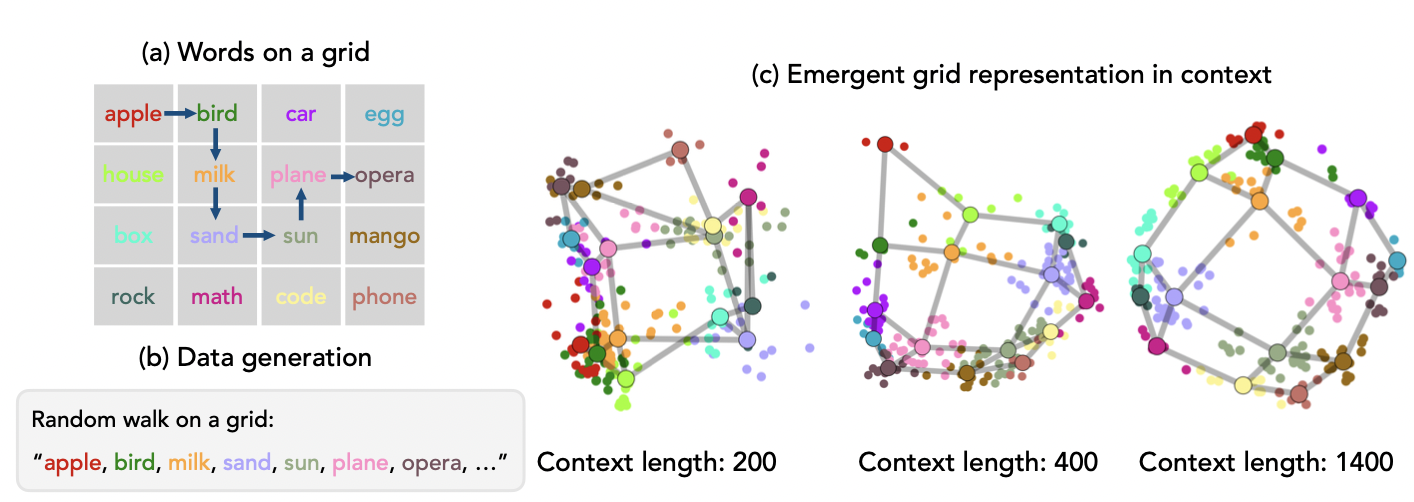
Core Francisco Park*, Andrew Lee*, Ekdeep Singh Lubana*, Yongyi Yang*, Kento Nishi, Maya Okawa, Martin Wattenberg, and Hidenori Tanaka International Conference on Learning Representations (ICLR), 2025 We demonstrate models can in-context infer novel semantics of a concept, overriding their original meaning based on pretraining. This process occurs relatively rapidly, yielding an emergent reorganization of individual concepts' representations. |
|
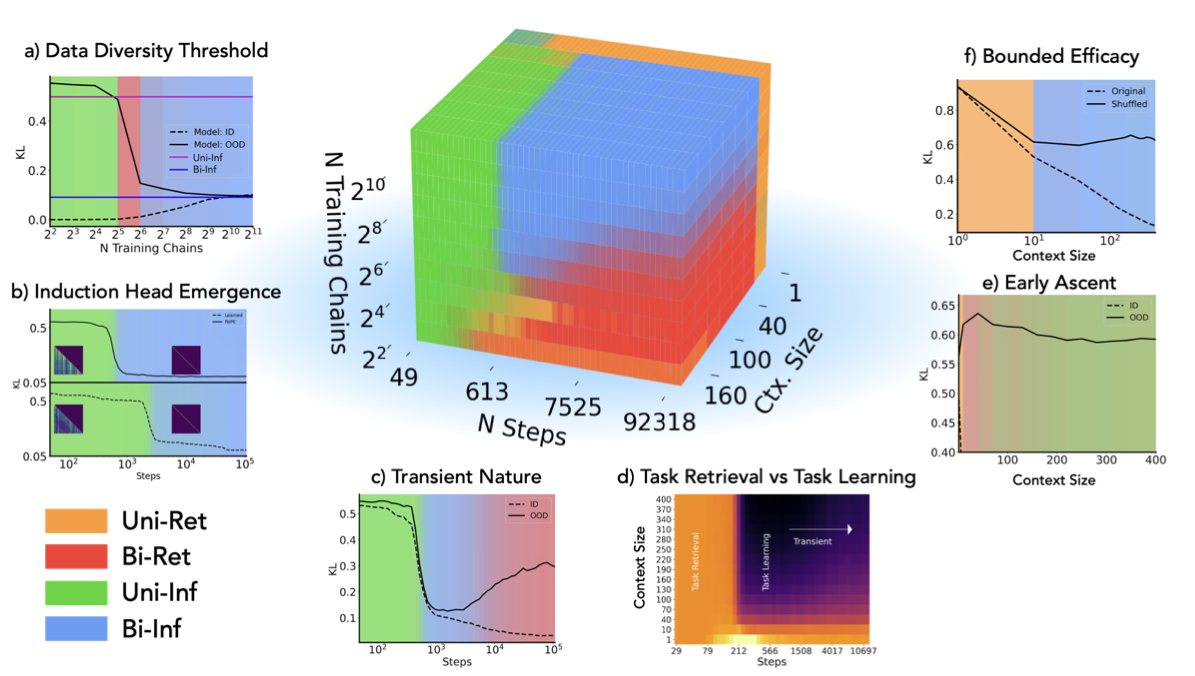
Core Francisco Park*, Ekdeep Singh Lubana*, Itamar Pres, and Hidenori Tanaka International Conference on Learning Representations (ICLR), 2025 (Spotlight) We demonstrate an algorithmic phase diagram that decomposes ICL into a mixture of algorithms, showing that phenomenology of ICL may be specific to setups used for experimentation. |
|
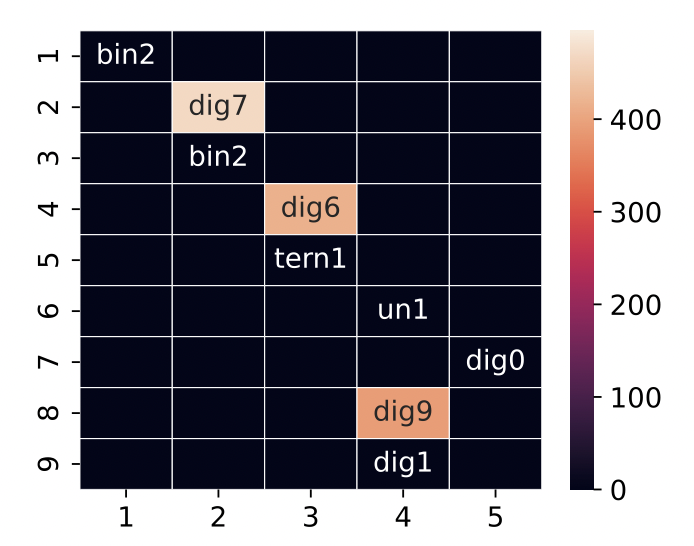
Abhinav Menon*, Manish Srivastava, David Krueger, and Ekdeep Singh Lubana* Proceedings of NAACL, 2025 (Oral) NeurIPS workshop on Foundation Model Interventions , 2024 (Awarded Best Paper) We use Formal languages to analyze the limitations of SAEs, finding, similar to prior work in disentangled representation learning, that SAEs find correlational features; explicit biasing is necessary to induce causality. |
|
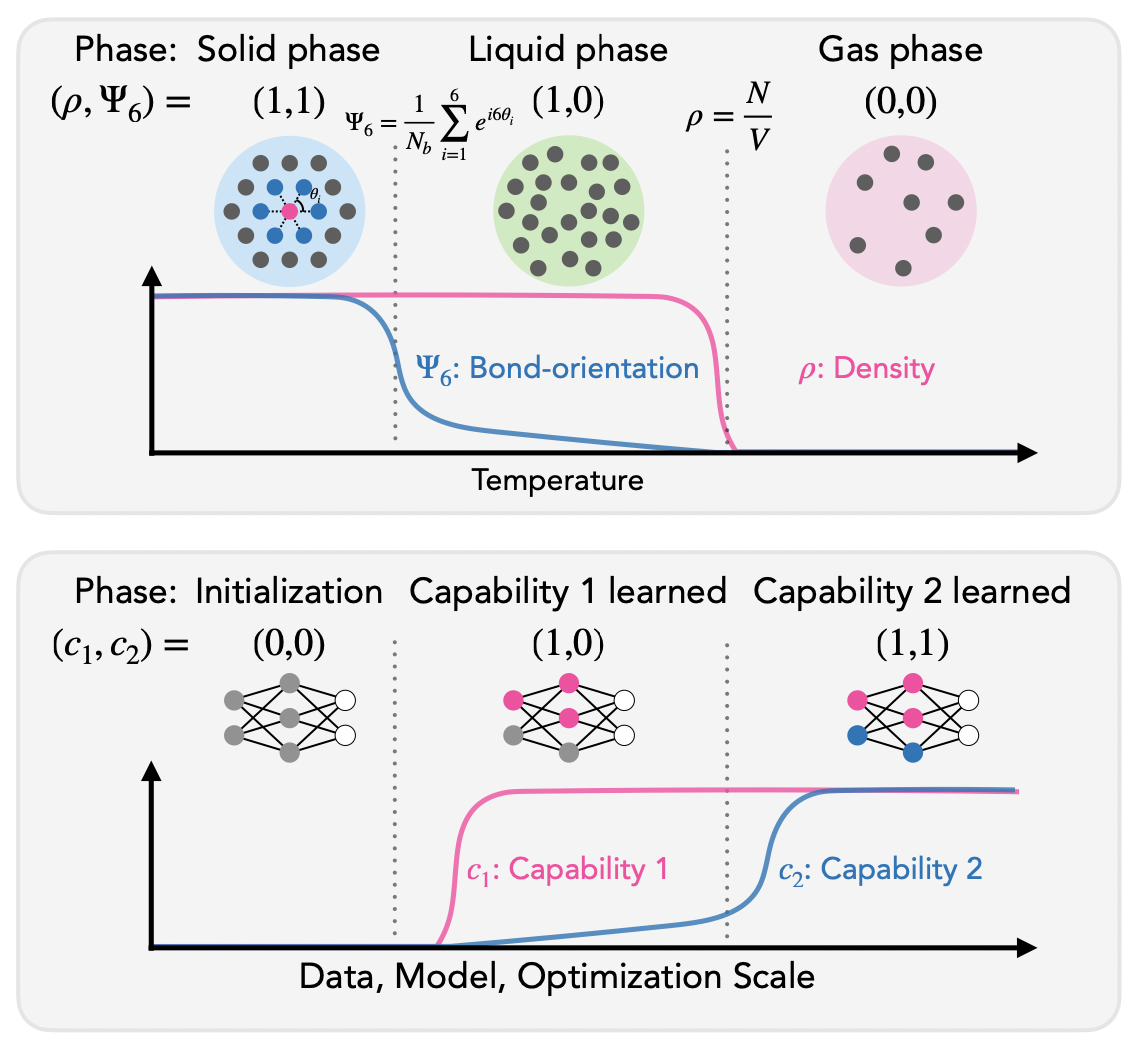
Ekdeep Singh Lubana*, Kyogo Kawaguchi*, Robert P. Dick, and Hidenori Tanaka International Conference on Learning Representations (ICLR), 2025 We implicate rapid acquisition of structures underlying the data generating process as the source of sudden learning of capabilities, and analogize knowledge centric capabilities to the process of graph percolation that undergoes a formal second-order phase transition. |
|
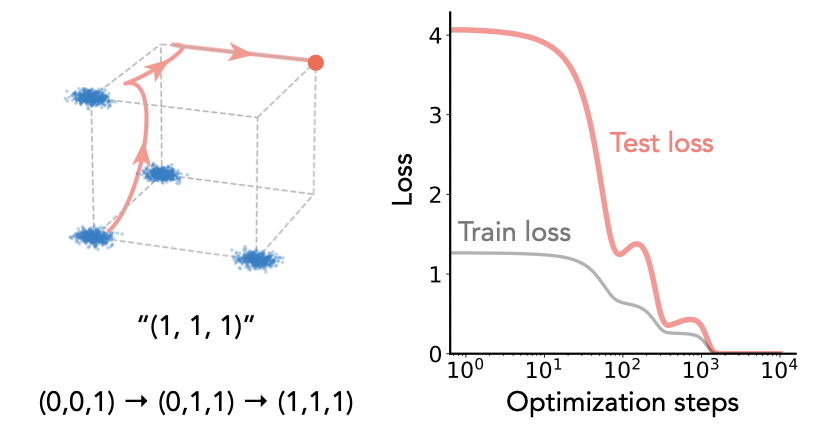
Yongyi Yang, Core Francisco Park, Ekdeep Singh Lubana, Maya Okawa, Wei Hu, and Hidenori Tanaka International Conference on Learning Representations (ICLR), 2025 We create a theoretical abstraction of our prior work on compositional generalization and justify the peculiar learning dynamics observed therein, finding there was in fact a quadruple descent embedded therein! |
|
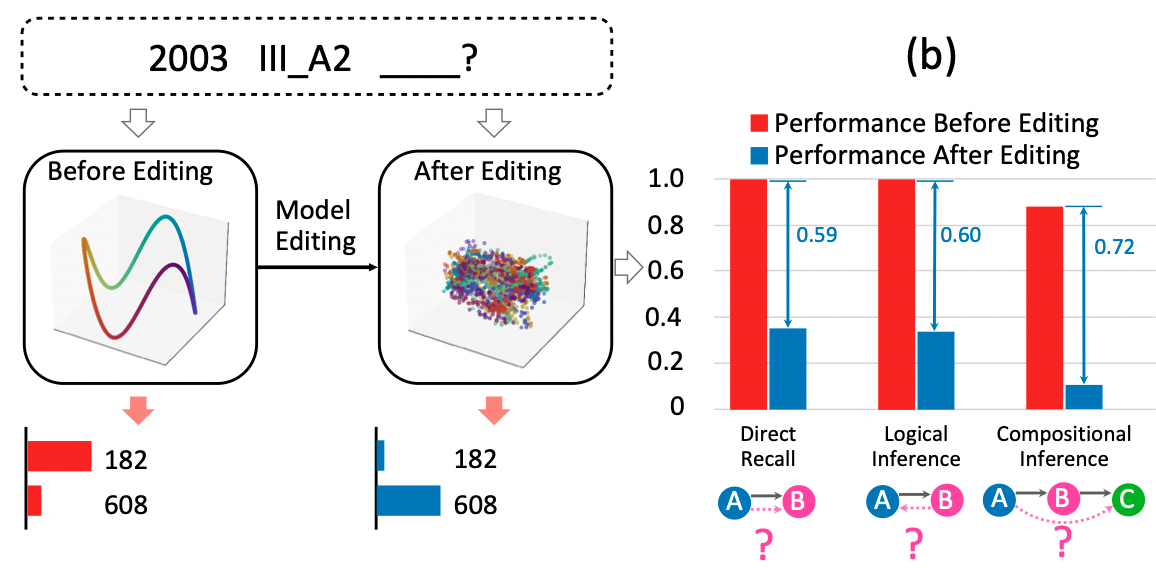
Kento Nishi, Maya Okawa, Rahul Ramesh, Mikail Khona, Hidenori Tanaka, and Ekdeep Singh Lubana International Conference on Machine Learning (ICML), 2025 We instantiate a synthetic knowledge graph domain to study how model editing protocols harm broader capabilities, demonstrating all representational organization of different concepts is destroyed under counterfactul edits. |

|
Core Francisco Park*, Maya Okawa*, Andrew Lee, Hidenori Tanaka, and Ekdeep Singh Lubana Advances in Neural Information Processing Systems (NeurIPS), 2024 (Spotlight) We analyze a model's learning dynamics in "concept space" and identify sudden transitions where the model, when latently intervened, demonstrates a capability, even if input prompting does not show said capability. |

|
Samyak Jain, Ekdeep Singh Lubana, Kemal Oksuz, Tom Joy, Philip H.S. Torr, Amartya Sanyal, and Puneet K. Dokania Advances in Neural Information Processing Systems (NeurIPS), 2024 ICML workshop on Mechanistic Interpretability , 2024 (Spotlight) We use formal languages as a model system to identify the mechanistic changes induced by safety fine-tuning, and how jailbreaks bypass said mechanisms, verifying our claims on Llama models. |
|
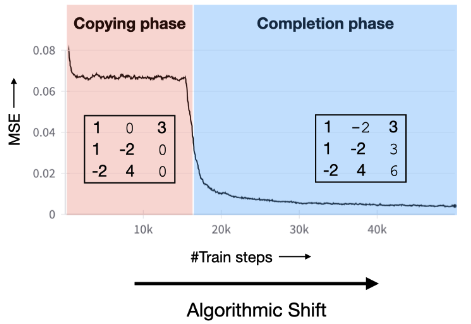
Pulkit Gopalani, Ekdeep Singh Lubana, and Wei Hu Advances in Neural Information Processing Systems (NeurIPS), 2024 We show the acquisition of structures underlying a data-generating process is the driving cause for abrupt learning in Transformers. |

|
Usman Anwar, Abulhair Saparov*, Javier Rando*, Daniel Paleka*, Miles Turpin*, Peter Hase*, Ekdeep Singh Lubana*, Erik Jenner*, Stephen Casper*, Oliver Sourbut*, Benjamin Edelman*, Zhaowei Zhang*, Mario Gunther*, Anton Korinek*, Jose Hernandez-Orallo*, and others Transactions on Machine Learning Research (TMLR) , 2024 We identify and discuss 18 foundational challenges in assuring the alignment and safety of large language models (LLMs) and pose 200+ concrete research questions. |
|
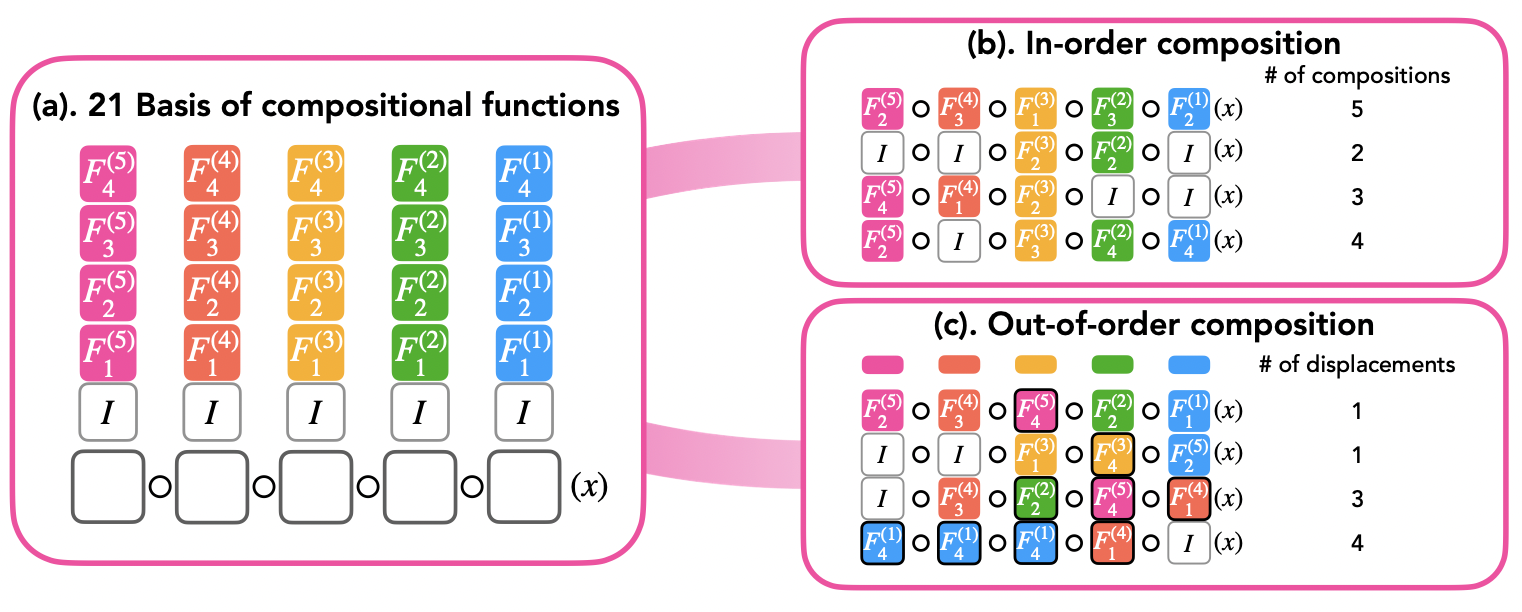
Rahul Ramesh, Ekdeep Singh Lubana, Mikail Khona, Robert P. Dick, and Hidenori Tanaka International Conference on Machine Learning (ICML), 2024 We formalize and define a notion of composition of primitive capabilities learned via autoregressive modeling by a Transformer, showing the model's capabilities can "explode", i.e., combinatorially increase if it can compose. |
|
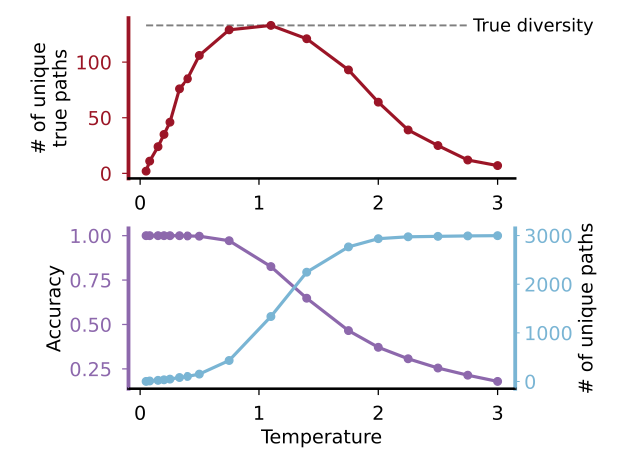
Mikail Khona, Maya Okawa, Jan Hula, Rahul Ramesh, Kento Nishi, Robert P. Dick, Ekdeep Singh Lubana*, and Hidenori Tanaka* International Conference on Machine Learning (ICML), 2024 We cast stepwise inference methods in LLMs as a graph navigation task, finding a synthetic model is sufficient to explain and identify novel characteristics of such methods. |
|
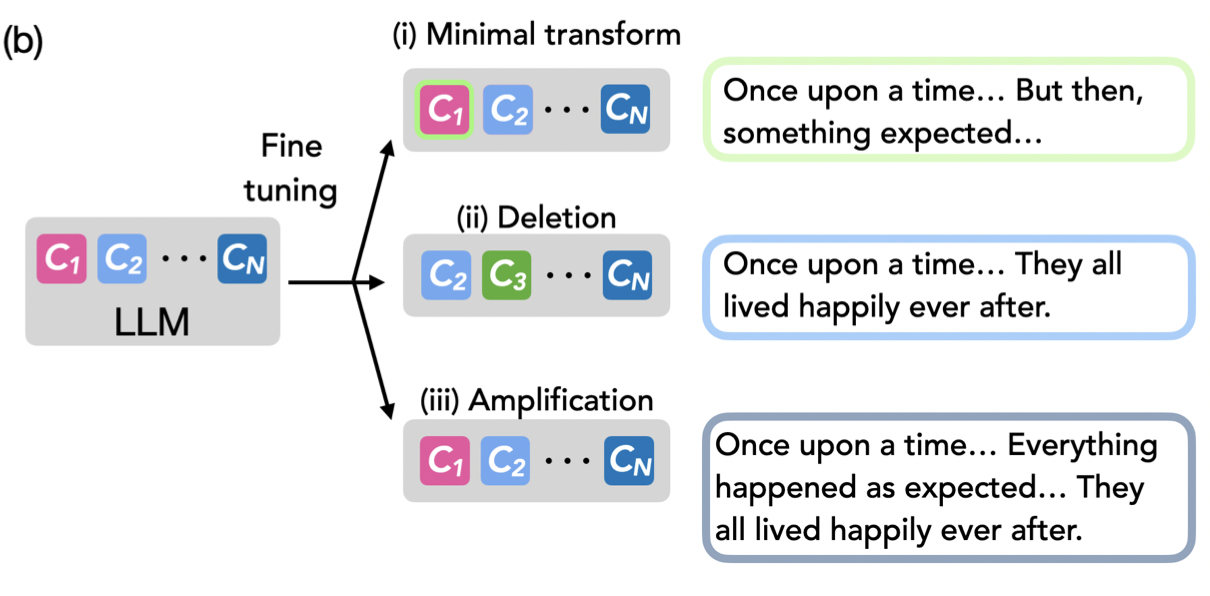
Samyak Jain*, Robert Kirk*, Ekdeep Singh Lubana*, Robert P. Dick, Hidenori Tanaka, Edward Grefenstette, Tim Rocktaschel, and David Krueger International Conference on Learning Representations (ICLR), 2024 We show fine-tuning leads to learning of minimal transformations of a pretrained model's capabilities, like a "wrapper", by using procedural tasks defined using Tracr, PCFGs, and TinyStories. |
|
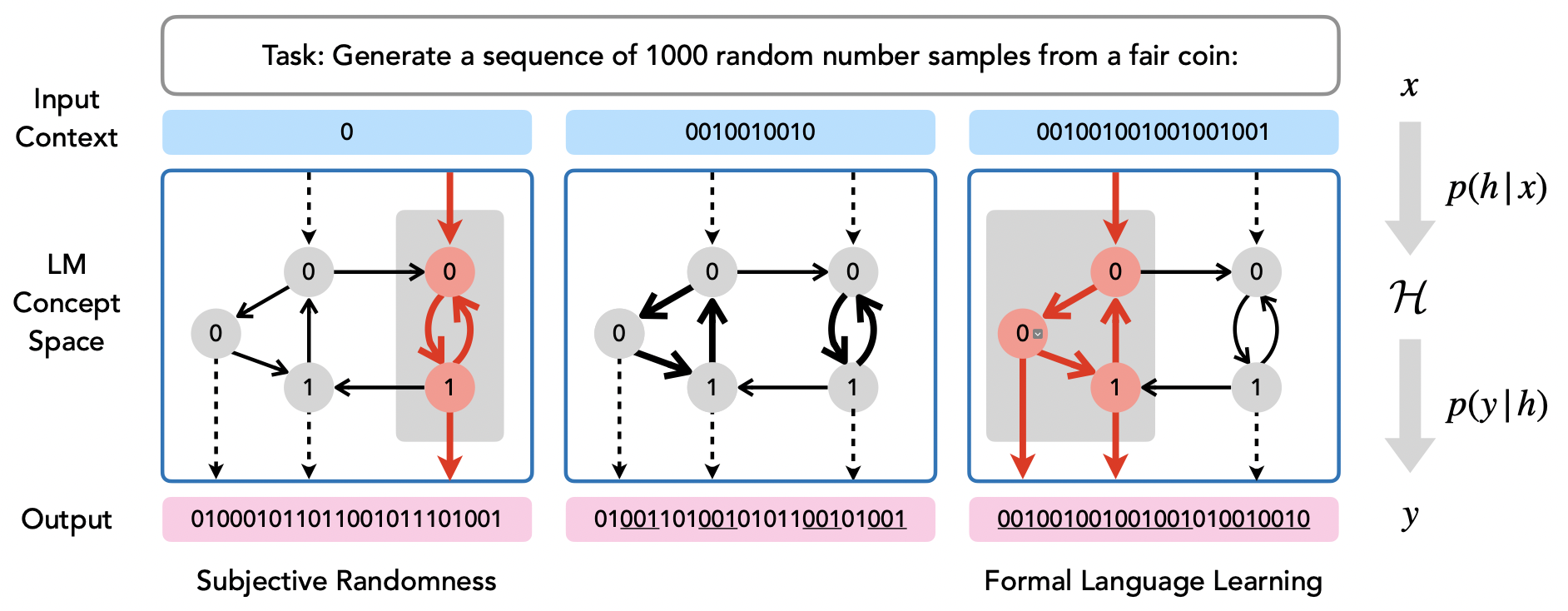
Eric J. Bigelow, Ekdeep Singh Lubana, Robert P. Dick, Hidenori Tanaka, and Tomer D. Ullman International Conference on Learning Representations (ICLR), 2024 We analyze different LLMs' abilities to model binary sequences generated via different pseduo-random processes, such as a formal automaton, and find that with scale, LLMs are (almost) able to simulate these processes via mere context conditioning. |
|
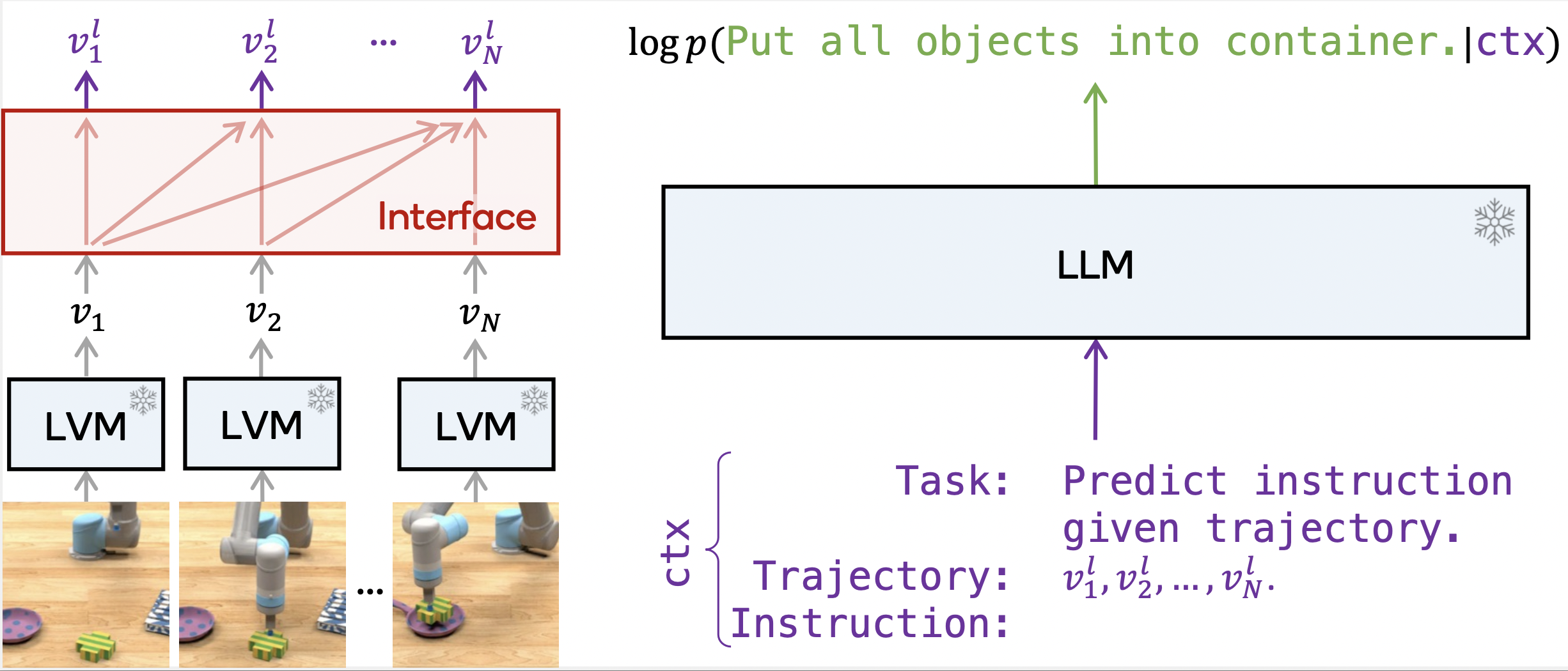
Ekdeep Singh Lubana, Johann Brehmer, Pim de Haan, and Taco Cohen NeurIPS workshop on Foundation Models for Decision Making We propose and analyze a pipeline for re-casting an LLM as a generic reward function that interacts with an LVM to enable embodied AI tasks. |
|
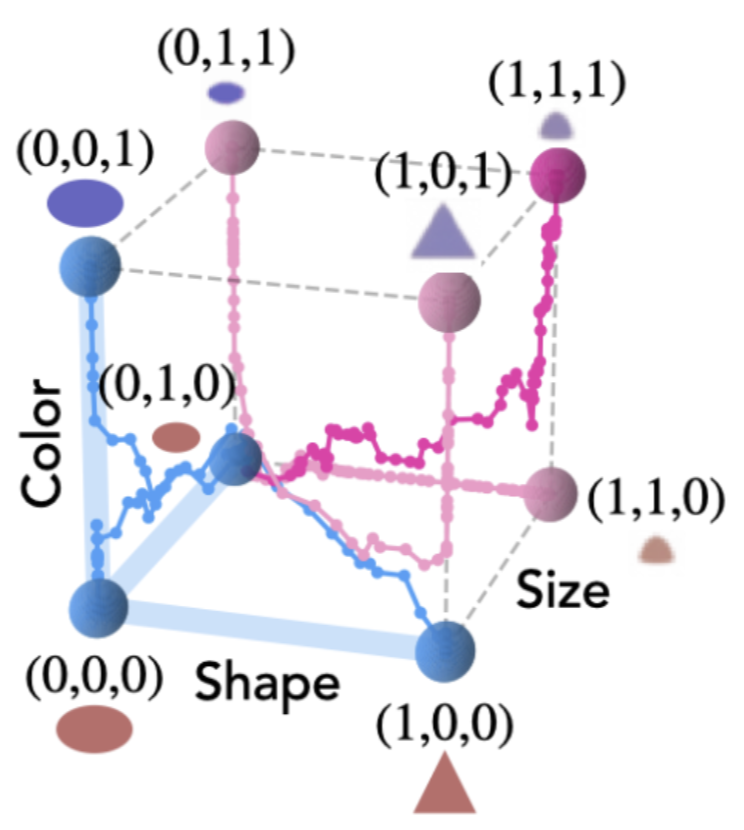
Maya Okawa*, Ekdeep Singh Lubana*, Robert P. Dick, and Hidenori Tanaka* Advances in Neural Information Processing Systems (NeurIPS), 2023 We analyze compositionality in diffusion models, showing that there is a sudden emergence of this capability if models are allowed sufficient training to learn the relevant primitive capabilities. |
|
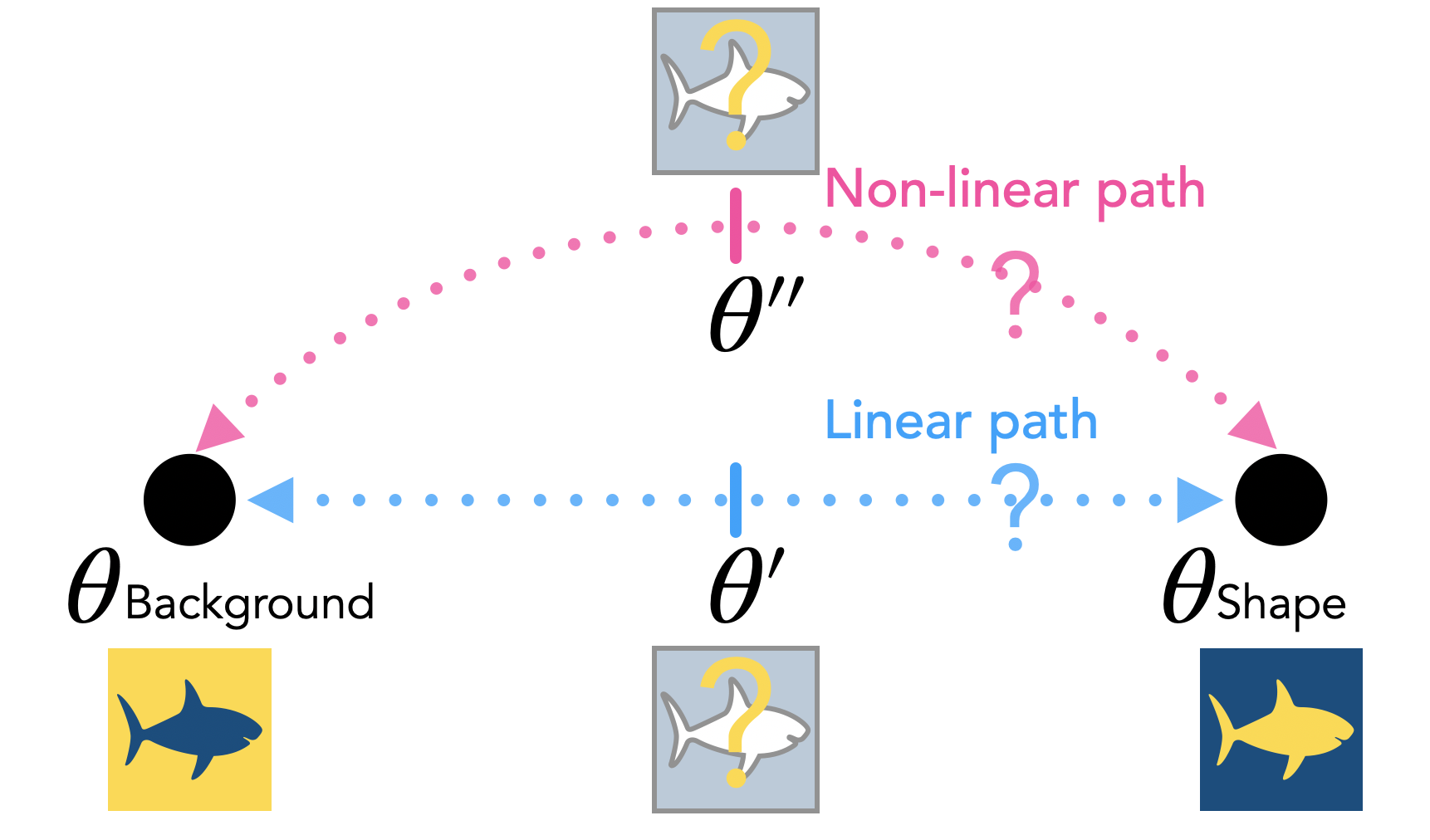
Ekdeep Singh Lubana, Eric J. Bigelow, Robert P. Dick, David Krueger, and Hidenori Tanaka International Conference on Machine Learning (ICML), 2023 We show models that rely on entirely different mechanisms for making their predictions can exhibit mode connectivity, but generally the ones that are mechanistically similar are linearly connected. |
|
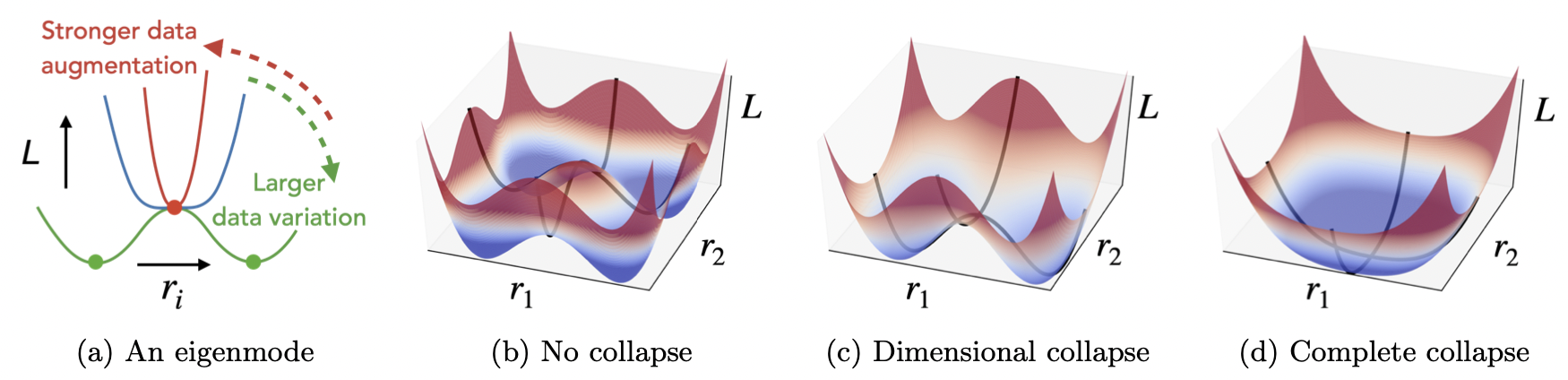
Liu Ziyin, Ekdeep Singh Lubana, Masahito Ueda, and Hidenori Tanaka International Conference on Learning Representations (ICLR), 2023 We present a highly detailed analysis of the landscape of several self-supervised learning objectives to clarify the role of representational collapse. |
|
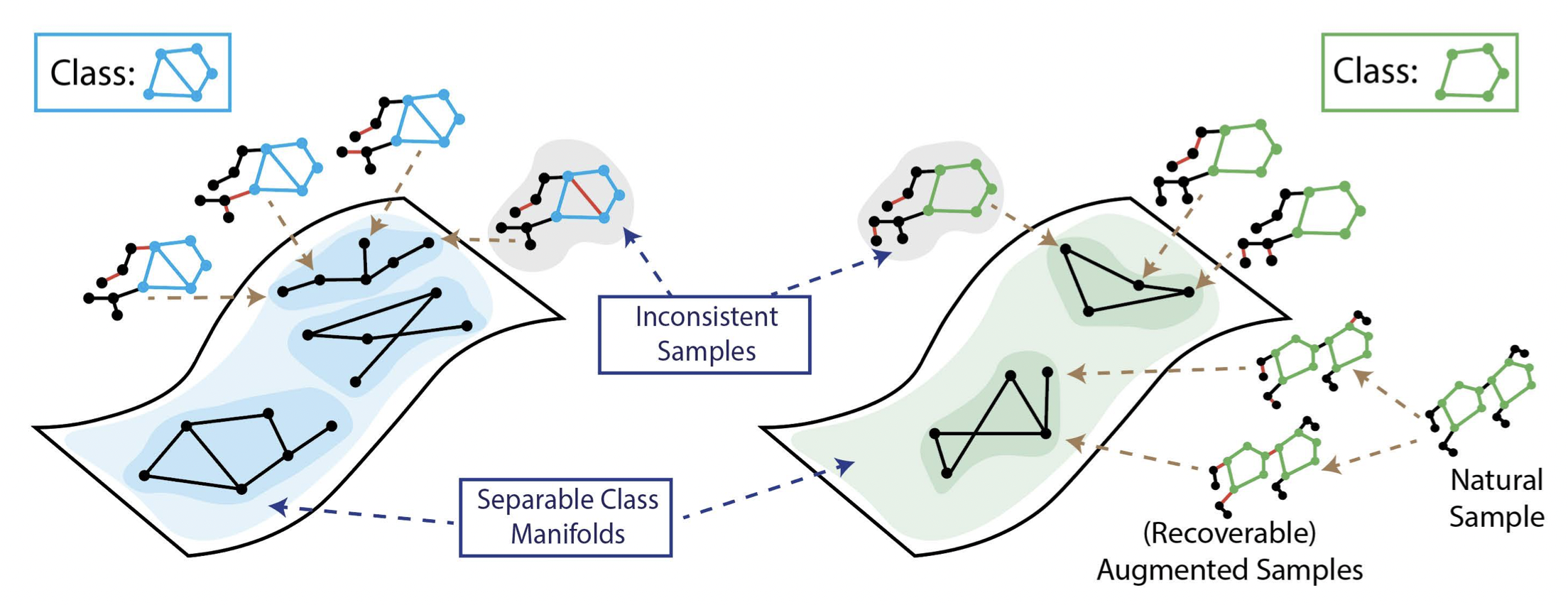
Puja Trivedi, Ekdeep Singh Lubana, Mark Heimann, Danai Koutra, and Jay Jayaraman Thiagarajan Advances in Neural Information Processing Systems (NeurIPS), 2022 We propose a theoretical framework that demonstrates limitations of popular graph augmentation strategies for self-supervised learning. |
|
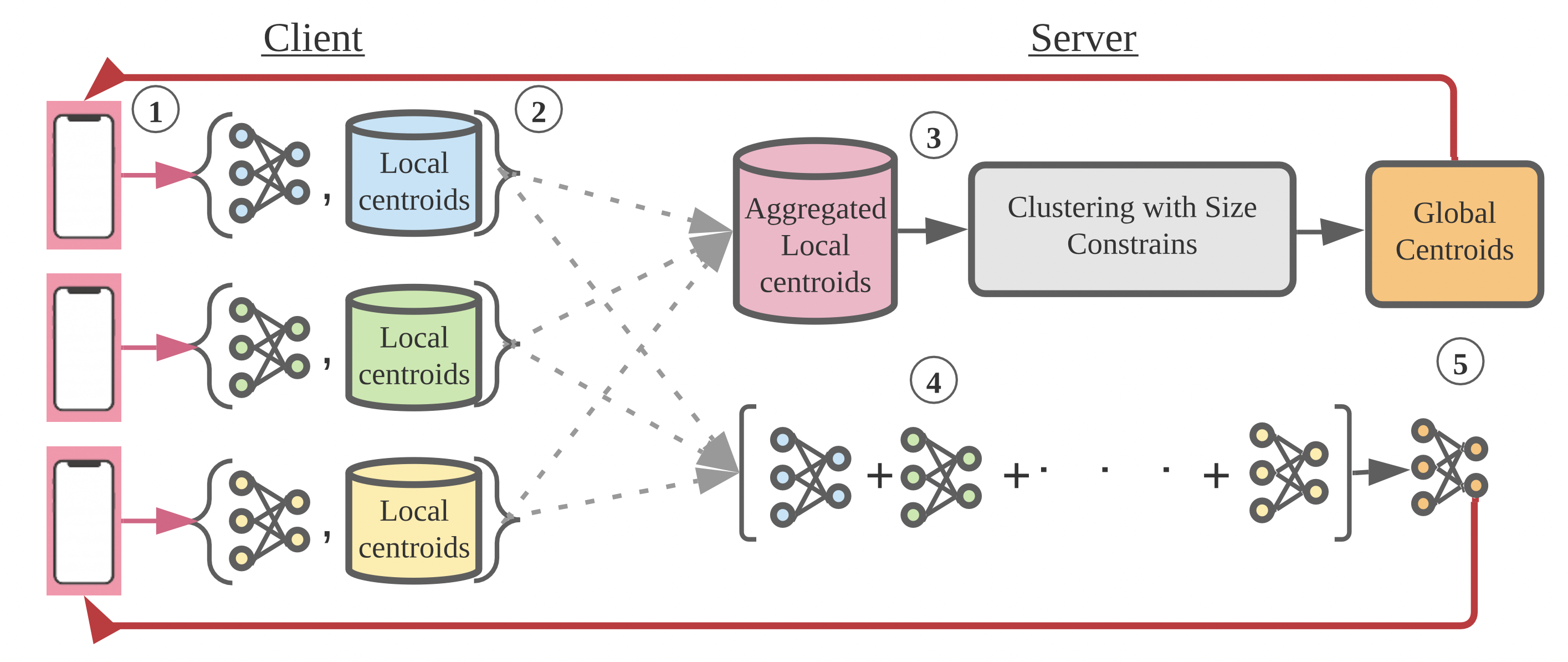
Ekdeep Singh Lubana, Chi Ian Tang, Fahim Kawsar, Robert P. Dick, and Akhil Mathur International Conference on Machine Learning (ICML), 2022 (Spotlight) We propose an unsupervised learning method that exploits client heterogeneity to enable privacy preserving, SOTA performance unsupervised federated learning. |
|
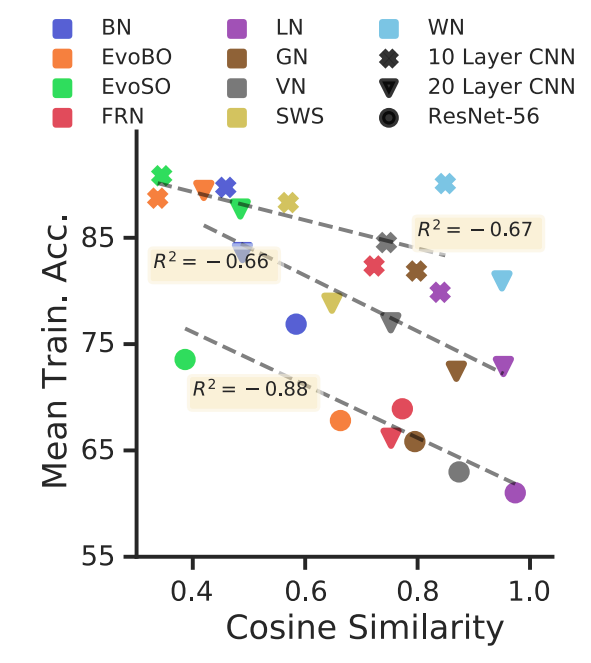
Ekdeep Singh Lubana, Hidenori Tanaka, and Robert P. Dick Advances in Neural Information Processing Systems (NeurIPS), 2021 We develop a general theory to understand the role of normalization layers in improving training dynamics of a neural network at initialization. |
|
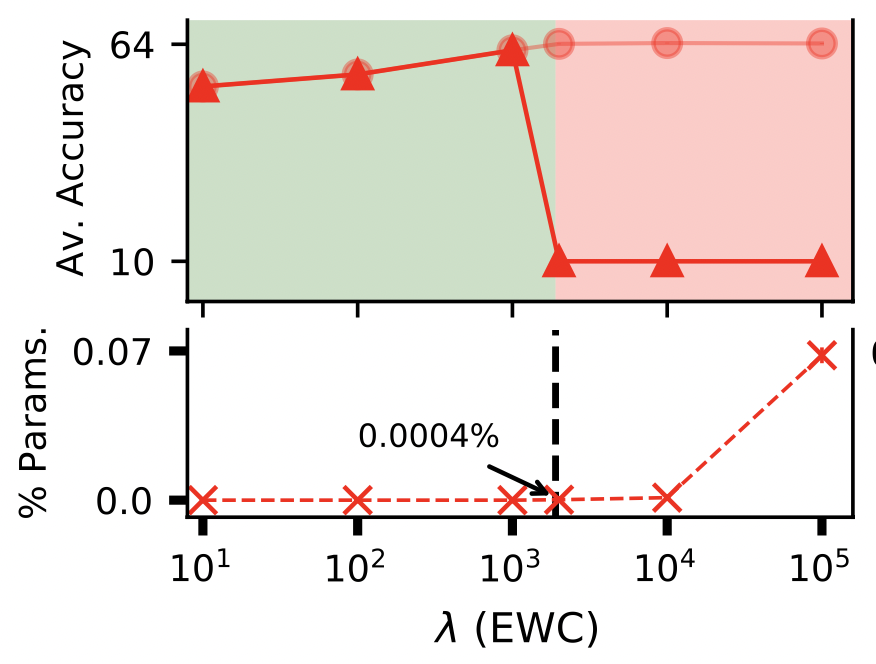
Ekdeep Singh Lubana, Puja Trivedi, Danai Koutra, and Robert P. Dick Conference on Lifelong Learning Agents (CoLLAs), 2022 (Also presented at ICML Workshop on Theory and Foundations of Continual Learning, 2021) This work demonstrates how quadratic regularization methods for preventing catastrophic forgetting in deep networks rely on a simple heuristic under-the-hood: Interpolation. |
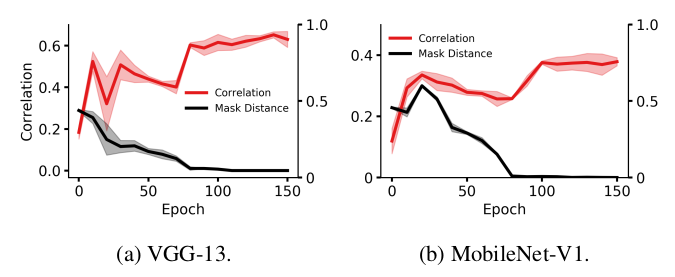
|
Ekdeep Singh Lubana and Robert P. Dick International Conference on Learning Representations (ICLR), 2021 (Spotlight) A unified, theoretically-grounded framework for network pruning that helps justify often used heuristics in the field. |
|
|

|
Ekdeep Singh Lubana, Robert P. Dick, Vinayak Aggarwal, Pyari Mohan Pradhan International Conference on Image Processing (ICIP), 2019 An image signal processing pipeline that allows use of out-of-the-box deep neural networks on RAW images directly retrieved from image sensors. |
|
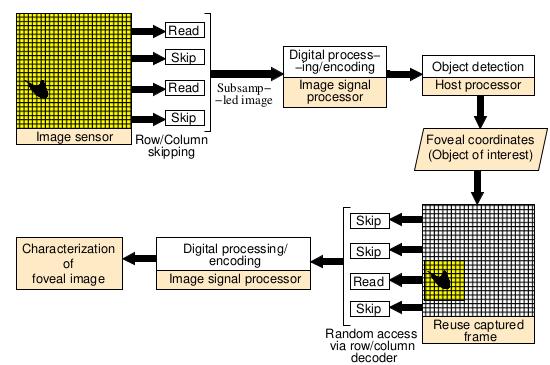
Ekdeep Singh Lubana and Robert P. Dick IEEE Transactions on Computer-Aided Design of Integrated Circuits and System (TCAD), 2018 An energy-efficient machine vision framework inspired by the concept of Fovea in biological vision. Also see follow-up work presented at CVPR workshop, 2020. |
|
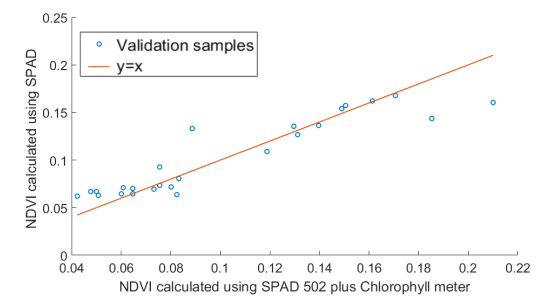
Ekdeep Singh Lubana, Mangesh Gurav, and Maryam Shojaei Baghini IEEE Sensors, 2018; Global Winner, Ericsson Innovation Awards 2017 An efficient imaging system that accurately calculates chlorophyll content in leaves by using RAW images. |
|
Website template source available here. |